I spent this week working on my webapp project.
For this project I had chosen to use ReactJS for the client side code. Additionally I was using a home-grown flux implementation for “gluing” the application together.
I was reading some general training material on Reactive programming and Flux and I realized my home-grown implementation might not have been as true to the Flux mindset as I originally thought.
So this week I explored whether to continue to use my existing implementation or choose one of the many pre-canned implementations.
For my implementation, I had three types of Actions, ServerActions, ResultActions, and ViewActions. I had one ActionCreator class that would create an Action object using one of these types and then that Action would be sent to my single Dispatcher class that would handle all actions.
Each Action had a type attribute that specified what action to take.
My Dispatcher class would inspect the Action type attribute and then directly call the appropriate method whether it be on my web service provider or a store directly.
This worked well but after reading more about general Reactive programming, I realized that although my intent was good I was probably not fully embracing the reactive style of programming and more particularly a “correct” Flux implementation.
This made me worry if I might hit a “maintenance wall” as my application grows.
In my mind, a “maintenance wall” is a situation in your code where you
made a design decision early on that later down the road you realize was a
poor decision. You are then left with a decision to either continue
using the incorrect design or refactor like a mad-man until you fix
it.If you can avoid these poor decisions early it is a “win” for you future self. When using a new technology you are just learning, I believe, the way you “win” is by following the path and advice of more seasoned developers in that particular technology.
As you get more seasoned in that technology you build up a toolset and come to your own conclusions of how best to use the technology but until then you have to rely on the expertise of others. Sometimes those “experts” will lead you in the wrong direction, sometimes not, it just comes with the territory.
That was the situation I was facing.
The problems I saw with my current implementation was there was too much coupling between the Dispatcher and the Action handler code.
Additionally, my web service handler was directly calling methods on the various Store objects when it got results back from the server. Again another needless coupling.
In short, my implementation had a lot of coupling between classes. This seemed very much like an anti-pattern when using reactive programming. So I decided it was time to find a more “correct” design for my flux implementation.
I knew I didn’t need a whole sale replacement of what I had, just a slight course correction. I eventually ran across the ‘flux-rails-assets’ gem and decided this was what I was looking for. Or at least it was the start of what I needed
This gem provides a Dispatcher class and an EventEmitter class. You create one Dispatcher implementation and all your Stores are instances of the EventEmitter class and each one registers a single “action handler” callback function to the Dispatcher to listen for when Actions are sent.
This way ALL Stores “see” all Actions but only handle the ones they are interested in.
This is a lot better than my implementation as the code for handling actions and the Stores they affect are all collated together. A maintenance win.
Finally, components (think UI components) register with the Store instances to be notified when the Store changes.
Unfortunately, since all of my home-grown Flux code was written in CoffeeScript and the gem was not, it presented a bit of a challenge on how to integrate it.
Because of this I was not able to use the “extends” keyword from CoffeeScript to extend the EventEmitter class like I had hoped for. Well, at least I couldn’t figure out how to make it work.
If someone knows how please let me know as I don’t do a lot of
CoffeeScript in my day job so I may have missed a nuance of the
language that would allow me to do it.
So what I chose to do, was for each store I had, have it own an instance of an EventEmitter. So for my SessionStore the top part of the code looked like this:
root = exports ? this
class SessionStore
loggedInProfile = null
emitter = new EventEmitter
To allow components to be notified when the Store changes I wrapped calls to the emitter instance like so:
emit: (type) ->
emitter.emit(type)
Then when a component registered with the Store for an event I would add that to the embedded emitter. Here is the add and remove listeners for a user’s profile in my SessionStore object:
addProfileUpdatedListener: (callback) ->
emitter.addListener(Events.PROFILE_UPDATED, callback)
removeProfileUpdatedListener: (callback) ->
emitter.removeListener(Events.PROFILE_UPDATED, callback)
The next big hurdle was how to attach a Store to the single AppDispatcher class supplied by flux-rails-assets. For each Store a action handler needs to be registered in the AppDispatcher.
The AppDispatcher will then call the action handler for each registered Store and each Store will do something with the actions it is interested in. The key point here is each Store gets every action.
The big issue I had here was how to attach the Store to the dispatcher. Here was the implementation for SessionStore I got to work after much trial and error.
root.SessionStore = new SessionStore
root.SessionStore.dispatchToken = AppDispatcher.register(SessionStore.handleAction)
The problem always revolved around the issue of what “this” was at the
time of the call
Now it was just a matter of wiring everything together. I will use the feature of the user updating their Profile as an example.
The SessionActionCreator for the update profile action looks like this:
updateProfile: (profile) ->
action =
type: ServerActions.UPDATE_LOGGED_IN_PROFILE
profile: profile
AppDispatcher.dispatch(action)
This is called by a component when the profile needs to be updated.
In the SessionStore’s actionHandler method it handles the UPDATE_LOGGED_IN_PROFILE Action like this:
@handleAction: (action) ->
type = action.type
console.log("SessionStore is handling: "+ type)
switch type
when ServerActions.UPDATE_LOGGED_IN_PROFILE
WebAPIUtils.updateProfile(action)
The updateProfile method in the WebAPIUtils class is called next and looks like this:
@updateProfile: (action) ->
console.log("WebAPIUtils.updateProfile called")
$.ajax({
url: "/update_profile"
dataType: 'json'
type: 'PUT'
data: { profile: action.profile }
success: (data) ->
SessionActionCreator.profileUpdated(data.profile)
error: (xhr, status, err) ->
console.error("/update_profile", status, err.toString())
})
Notice the success handler funnels the result back through the SessionActionCreator. Here is the profileUpdated method:
profileUpdated: (profile) ->
action =
type: ResultActions.LOGGED_IN_PROFILE_UPDATED
profile: profile
AppDispatcher.dispatch(action)
This gets passed back to the SessionStore via the AppDispatcher. Here is the relevant part of the actionHandler method:
when ResultActions.LOGGED_IN_PROFILE_UPDATED
SessionStore::setLoggedInProfile(action.profile)
SessionStore::emit(Events.PROFILE_UPDATED)
This code updates the profile stored in the store and them emits the PROFILE_UPDATED event which registered components are listening to.
So now after making this slight course correction I have the following results.
- All Actions are created by “action creator” class instances
- The generated actions all go through the single AppDispatcher
- All Stores see all Actions
- There is a Store instance for each of the types of objects the app has
- Components register with the various Stores for events they are interested in
- Home-grown code has been removed
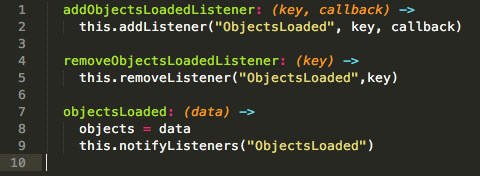
One thing that I don’t like is the registering of the component listening functions. In my old implementation a component would register using a key and a callback function. So when it was time to remove itself, it just used the key.
Now with this implementation I only use a function (because that is all the EventEmitter takes) so for a component to deregister it must pass the original function it registered with. I’m not sure why but that doesn’t feel right to me.
I will need to “noodle” on that one a bit.
Till next time.